
Battle of the Digital Easels: A Visual Test of Today's Top AI Models
A side-by-side visual comparison of how today's top models handle artistic, abstract, and business-centric image requests.

Several of the major large language models (LLMs) can generate images, which is incredibly helpful if you ever need to create content. While they are constantly upgrading their capabilities, I decided to take a quick look now that ChatGPT 5 has been released, and the xAI (Grok) team has been discussing their image and video creation capabilities lately.
I'm running three different prompts through ChatGPT 5, Gemini 2.5 Pro, and Grok 4 on August 14th, 2025.
ROUND 1:
"A highly detailed, low-poly digital art portrait of a St. Bernard dog. The dog is the main subject, positioned slightly to the left of the center, and is looking directly at the camera with a friendly expression and its mouth slightly open, revealing its tongue. To the right of the dog is a classic, silver, vintage-style studio microphone in a shock mount.
The entire image is rendered in a geometric, polygonal art style, composed of numerous small, sharp, triangular facets that create a "shattered glass" or crystallized effect. The color palette is warm and earthy, dominated by shades of brown, black, tan, and white for the dog's fur."
Grok:

ChatGPT:

Gemini:

In this first round, I like the Gemini photo the best, followed very closely by the ChatGPT photo, with Grok a distant third (Grok didn't apply the effect to the entire image - the ears and background remain fuzzy/untouched).
ROUND 2:
"The Tower to the Moon (and Then Some): If you printed all 1 quadrillion tokens onto paper, 300 words per page, standard thickness, the stack would soar nearly 158,000 miles high. That's two-thirds of the way to the Moon. It would tower 650 times higher than the International Space Station, 2,500 times taller than the edge of space, and still be visible on NASA's worry radar. It wouldn't just scrape the sky — it would take you on a paper elevator through the stratosphere, past orbit, and straight into the cold dark void."
This one is a little trickier, as I used text from a recent article and wanted to see how the models would process it.
Grok:

ChatGPT:
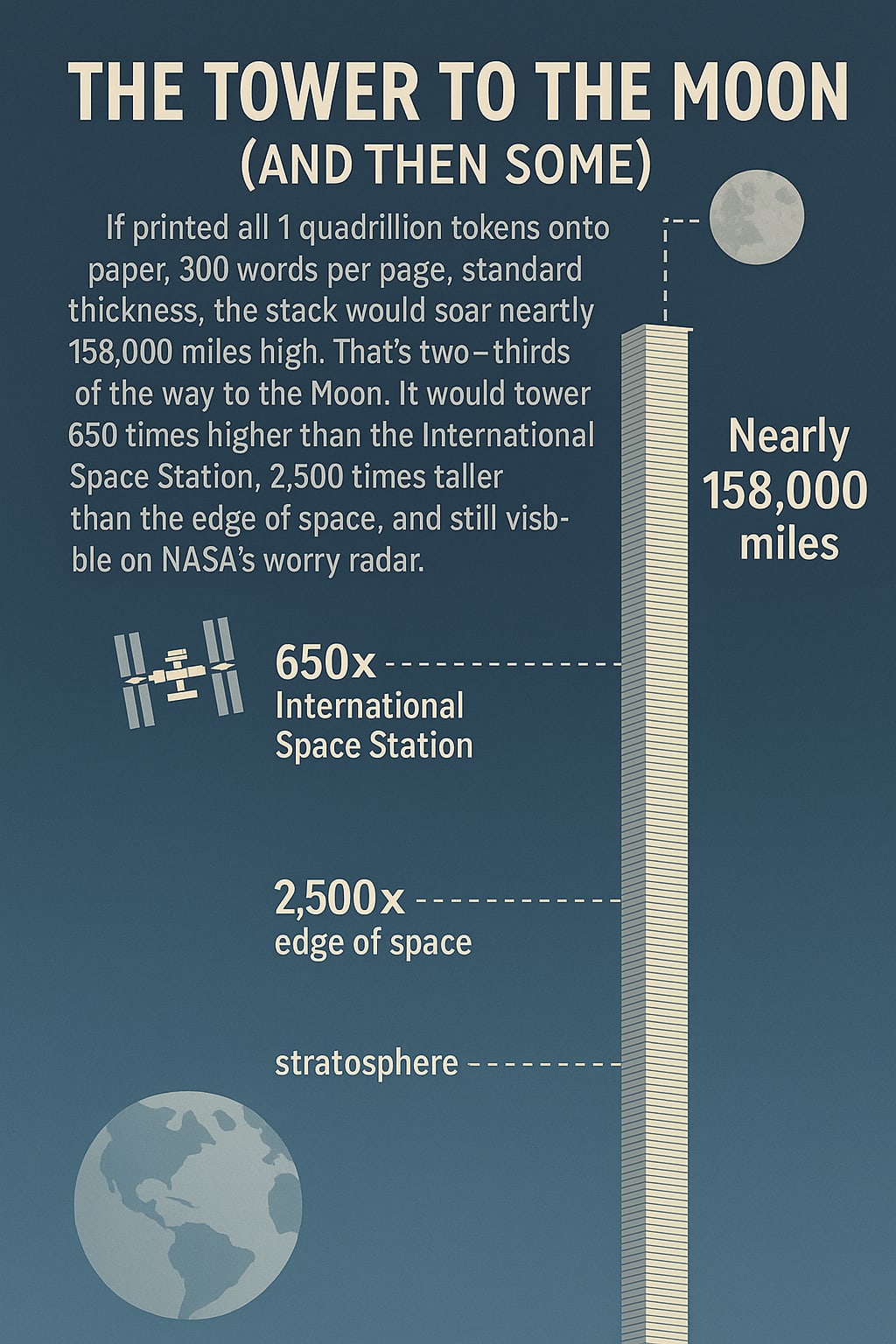
Gemini

In the second round, I again liked the Gemini photo the best - I thought it was the most interesting and aligned with the vision I had behind the text. I did like the ChatGPT infographic a lot. It was a good way to present the data and would definitely be an image I would use. The Grok one didn't do it for me.
Before we move on to round three, I'd like to share an approach I've been using to create descriptions for images. When I write an article (like my last one on GPT-5's Bumpy Start), I will often take my final article and dump it into ChatGPT or Gemini and say something like, "this is a blog post I just wrote: give me three very detailed image descriptions that I can use to create images for this post. be creative and professional." The following prompt came from that exact process.
ROUND 3:
"An overhead shot of a polished wooden desk where a blueprint for an "AI Integration Strategy" is laid out. The blueprint shows interconnected diagrams, flowcharts, and checkpoints, similar to an architectural plan. On the blueprint, there are handwritten notes in red ink like "Run side-by-side bakeoff" and "Create rollback muscle." A high-end laptop and a cup of coffee are placed next to the blueprint, conveying a sense of calm, deliberate planning and control."
GROK:
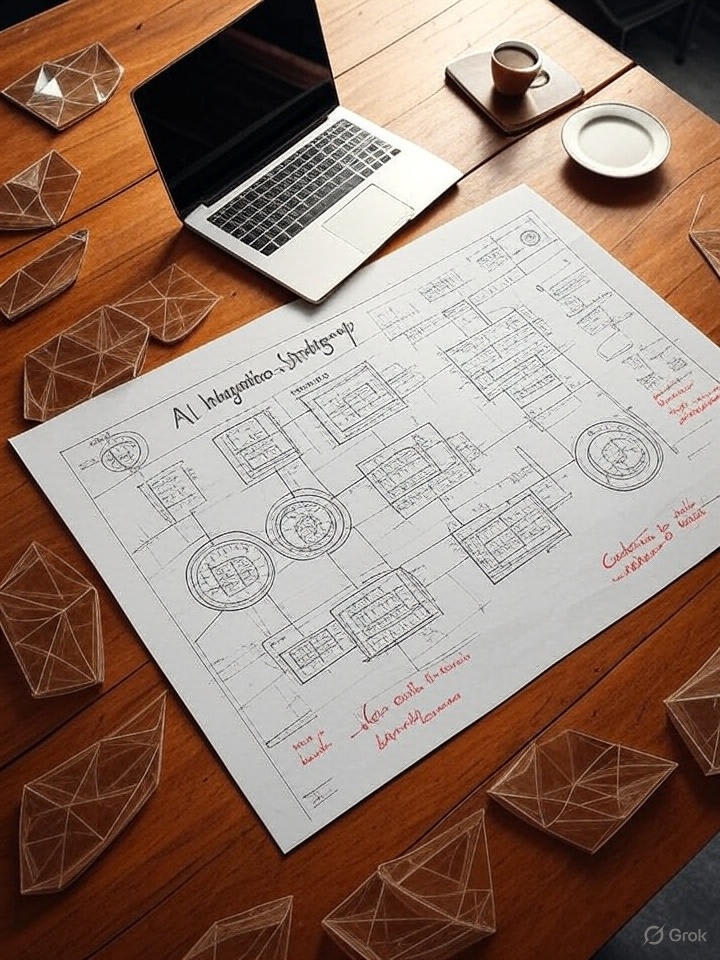
ChatGPT:

Gemini

In this round, I'm giving the win to ChatGPT. I prefer the visuals of the Gemini image slightly more, but ChatGPT got all the text correct, whereas the Gemini image contained a number of typos and made-up words. Grok's image to me was a bit weird - I didn't know what all the extra objects on the desk were supposed to be, and the text in the image was gibberish.
What do you think? Do you agree? Gemini and ChatGPT have really good imaging engines built into their core LLMs. You can create some amazingly complex and interesting imagery. Grok, on the other hand, still feels like it’s a couple of generations back in terms of refinement.
One thing I want to highlight is that if you want even better image generation capabilities and you are a Gemini subscriber, go over to AI Studio and try out their new Imagen 4 001 ultra model. You get several free runs with it as part of playing in the studio. It's vastly superior to all of these, and you can also output the images in 1K or 2K quality, gaining more control over the aspect ratio and number of outputs. Here are those same three prompts run through the latest Imagen 4 001 ultra model at 1K output (which was updated today).



It's great that these capabilities are built into these tools, and they just keep getting better and better.